
Research
Causal explanations provide a window into human causal understanding. When we explain why something happened, we externalize aspects of our causal representations, revealing not just what we know but how that knowledge is organized. My research pursues two complementary directions.
Producing explanations
Consider a forest fire sparked by lightning. The fire required both lightning and oxygen; without either, no combustion. Yet we cite the lightning as the cause, never the oxygen. This asymmetry—causal selection—reflects how our cognitive machinery represents and weighs causes. Our representations encode two things simultaneously: structure (discrete commitments about what causes what) and gradedness (continuous distinctions in importance). This duality is what Smolensky (1986) called the “Structure/Statistics Dilemma”—cognition appears both rule-governed and context-sensitive.
Structural causal models (SCMs), the dominant framework in philosophy and AI, capture structure through directed acyclic graphs but remain silent on how importance is computed over that structure. I address this gap through two lines of work: experiments on plural causal judgments that reveal the structure of our causal representations, and neurosymbolic models that compile logical causal structure into neural network architectures where gradedness emerges from continuous weights.

Learning from explanations
The same explanations that reveal our causal representations also shape them. How do sparse causal selection explanations, that mention just one or two relevant variables in a system, guide learners toward correct causal rules? My dissertation work proposes an attention-based account: explanations direct attention during learning, biasing gradient updates toward mentioned variables.
Currently, my work focuses on extending this to the self-explanation effect, i.e. the well-documented finding that explaining material to oneself improves learning in a variety of tasks. I ask what cognitive mechanisms underlie this effect and what sort of computational models can be built to capture the effect that explaining things to oneself has on learning.

Part I · Producing Explanations
Plural Causal Selection
Experiments on how people judge multiple causes cited together, revealing patterns incompatible with existing theories.

Prior work established that causal selection depends on normality: abnormal causes receive different treatment than routine ones. Conjunctive structures show abnormal inflation (rare causes gain credit), while disjunctive structures show abnormal deflation (common causes gain credit). But this work focused exclusively on singular causal claims—“E happened because of A.” What happens when multiple causes are cited together?
We conducted the first systematic experiments on plural causal judgments—statements like “E happened because of A and B” (Konuk, Goodale, Quillien, & Mascarenhas). Such judgments had received little study, perhaps because of a tempting deflationary hypothesis: that plural strength simply aggregates singular judgments. In a first experiment, we ruled this out directly. Participants evaluated both singular and plural causal claims for the same scenarios, and plural judgments were not predictable from singular ones. People evaluate plural causes as bona fide candidates whose counterfactual profile is apprehended directly rather than recomposed from parts.

Having established that plural judgments are genuinely holistic, we designed a second experiment to probe their structure more precisely. Participants played a game with an explicitly disjunctive rule: winning required either \((A \land B)\) or \((C \land D)\)—two routes to the same outcome.
A striking pattern emerged: participants strongly preferred “same-side” pairs (plurals on the same route, like A&B) over “cross-side” pairs that mix variables from different routes (like A&C). But the results for negative outcomes were deeply puzzling—indeed, incompatible with existing theories of causal judgment. Classical theories predict abnormal deflation for disjunctive structures, yet participants showed the opposite pattern: preference for surprising failures. Moreover, the same-side dominance that characterized wins disappeared entirely for losses.

I account for these patterns through the homogeneity hypothesis, inspired by the linguistic observation that natural language quantifiers resist mixed readings. Just as “The boys didn't leave” typically means “None of the boys left” (not merely “At least one didn't”), people interpret losing as all routes failing—collapsing the route structure. Formally, the standard negation target LOSE requires only that the active route fails:
But under homogeneity, the strengthened target LOSEstrong requires that every variable on every route takes a negative value:
This strengthened target is conjunctive—it flips the causal structure from disjunctive to conjunctive, explaining both the reversal of the normality effect (inflation instead of deflation) and the collapse of route structure (no more same-side preference, since all variables now participate in a single “route”).
Computational Modeling: A Neurosymbolic Account of Causal Selection
Neural networks constrained by logic, counterfactual simulation, and relevance propagation to compute causal importance.
Causal judgments depend not just on objective causal structure but on how that structure is mentally represented. Two systems with identical input-output behavior can yield different causal judgments if their internal representations encode different intermediate structure. Structural causal models (SCMs)—the dominant framework in philosophy and AI—miss this point: a DAG with edges from {A, B, C, D} to E treats all causes as participating in a single flat function, erasing the route structure that distinguishes \((A \land B) \lor (C \land D)\) from other four-variable rules.
I propose modeling internal causal structure using neural networks whose architecture is constrained by logic programming. The key idea is to represent causal rules as Horn clauses—logical formulas of the form Head ← Body:
Each clause represents one “route” to the outcome. Crucially, proving that the outcome obtains is existential (find any route that succeeds), while proving that it does not obtain is universal (show that every route fails). This existential–universal asymmetry in logic programming mirrors the asymmetry we observe between win and loss judgments.
The CILP algorithm (Garcez, Broda, & Gabbay, 2002) compiles these logic programs into neural networks with one hidden node per clause. Each hidden node computes a conjunction (AND of its inputs); the output node computes a disjunction (OR of hidden nodes). This creates a network architecture that is isomorphic to the logical structure of the rule—encoding route structure as a structural feature of the representation itself.
Counterfactual Simulation and Causal Importance
Given a neural network encoding causal structure, how does the cognitive system compute causal importance? I propose a three-stage process: (1) sample counterfactual worlds via MCMC, (2) update connection weights based on how each counterfactual changes the network's behavior, and (3) propagate relevance backward through the updated network to assign credit to input variables.
Stage 1: MCMC sampling. Starting from the observed world, the system explores neighboring counterfactual states by flipping individual variables. Transition probabilities depend on event normality (abnormal events are more likely to be flipped) and on whether flipping a variable would change the activation of any hidden node. This means the sampling process is sensitive to route structure—a variable that participates in an active route is harder to “undo” than one that is merely present.

Stage 2: Weight updates via Layer-wise Feedback Propagation (LFP). Each sampled counterfactual triggers a weight update. When flipping a variable changes the output, the connection weights along the affected pathway are strengthened; when it does not, they are weakened. Over many samples, weights accumulate evidence about each connection's causal relevance. This is a feedback-driven process analogous to Hebbian learning: connections that consistently participate in output-changing counterfactuals grow stronger.

Stage 3: Layer-wise Relevance Propagation (LRP). Finally, credit is distributed backward through the network using LRP. Starting from the output, each layer redistributes its relevance to the layer below in proportion to the (updated) connection weights. The final relevance scores at the input layer represent each variable's causal importance. The overall measure is:
where \(R_c\) is the LRP relevance of input \(c\), and \(\mathcal{C}(C, O)\) counts the number of edge-disjoint active routes from the candidate set \(C\) to the outcome \(O\). This parsimony term is what explains the same-side preference: causes operating through a single shared route score higher than causes that spread their contribution across multiple routes.

Part II · Learning from Explanations
Attention-Based Learning
How sparse causal explanations guide rule learning—an attention-based account outperforms Gricean inference.
How do causal explanations guide the acquisition of causal knowledge? An explanation like “E happened because of C” deliberately omits most of the causal picture—it says nothing about the other variables or the functional form of the rule. Yet such sparse signals seem remarkably effective at guiding learners. How can mentioning a single cause help someone infer a rule involving several variables?

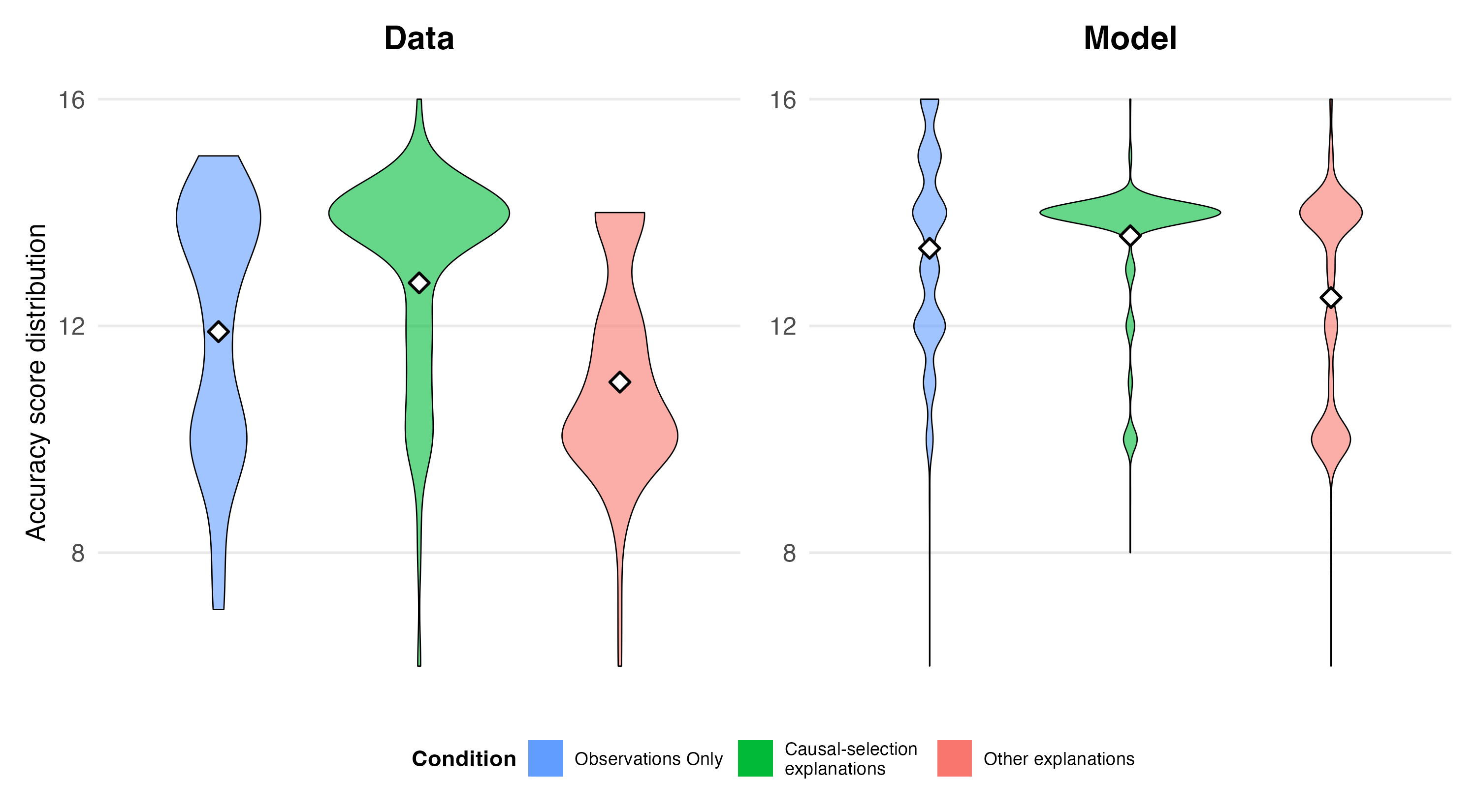
We developed a new paradigm to study this (Navarre, Konuk, Bramley, & Mascarenhas). Key findings: (i) causal selection explanations significantly help participants infer the correct rule; (ii) explanations citing any relevant variable (the “actual cause” condition) performed worse than observations alone—a surprising result given that these explanations provide strictly more information; (iii) participants showed a striking preference for simple (conjunctive) rules even when some explanations should have ruled them out.
Two competing accounts explain these patterns. The reverse-engineering account treats explanations as Gricean signals: the learner infers what rule hypotheses would lead a rational speaker to produce that particular explanation. This is essentially a pragmatic inference—“If the speaker chose to mention C, what must the underlying rule be for C to be the most relevant cause?”

I propose an alternative attention-based account: explanations direct attention to certain variables during learning. Mentioned variables are amplified in the learner's input representation; unmentioned variables are attenuated. When the learner updates their internal model via gradient descent, more gradient signal flows through attended (amplified) inputs, biasing the learned weights toward rules that assign those variables greater importance.
Three considerations favor the attention account. First, reverse-engineering cannot explain the simple-rule preference: when explanations contradicted simple rules, participants still preferred them—suggesting they weren't performing rational hypothesis elimination. Second, reverse-engineering predicts that more information should always help, but “any relevant variable” explanations actually hurt performance—attention naturally explains this, since diffuse attention across all variables provides no differential learning signal. Third, attention is computationally tractable: it integrates directly into gradient-based learning without requiring the learner to maintain and evaluate an exponentially growing space of rule hypotheses.
Publications
Interactive models
R Markdown documents with runnable code and detailed explanations of the computational models in my research.
Teaching
Contact
konuk at stanford dot edu