Causal Explanations and Continuous Computation
A précis of my doctoral dissertation, completed at Institut Jean Nicod (École Normale Supérieure) under the supervision of Salvador Mascarenhas.
Introduction
This dissertation investigates human causal understanding, that is, people's ability to represent and reason over the causal relations inherent to a system. Specifically, it examines the relation between our category of cause, on which rests our knowledge of what events count as causes for what outcomes, and the graded notions of causal strength and responsibility that underlie our intuition that the contribution made by a certain event is large or small. This requires a theory of the representations we use to encode causal systems, and a theory of how these representations are computed over.
Causal explanations provide the empirical counterpart to such a theory. When we explain why something happened, we externalize aspects of our causal representations, revealing not just what we know about a causal system but how that knowledge is mentally organized. Consider a forest fire sparked by lightning. The fire required both lightning and oxygen; without either, no combustion could occur. Yet we unhesitatingly cite the lightning as the cause, never the oxygen. This asymmetry is what philosophers and cognitive scientists call causal selection. Importantly, the causal facts do not force this choice upon us, as the fire depended on both factors equally; rather, it reflects how our cognitive machinery represents and weighs causes. This makes causal selection judgments a window into the representational and computational mechanisms by which we mentally apprehend causal systems.
In particular, they highlight two dimensions of our causal understanding. On the one hand, our representations encode structure: discrete commitments about what causes what. Causation runs from lightning and oxygen to fire, not the reverse. On the other hand, our representations support graded distinctions: lightning matters more than oxygen. This duality of discrete structure coexisting with continuous gradation is a special case of what Smolensky (1986) called the "Structure/Statistics Dilemma." Cognition appears both "hard" (rule-governed, honoring discrete logical constraints) and "soft" (context-sensitive, encoding information in continuous quantities that admit degrees). Traditional cognitive architectures tend to privilege one aspect at the expense of the other.
The dominant framework for modeling causal relations, Structural Causal Models (Pearl, 2009), addresses the "hard" side decisively. SCMs encode causal systems as directed acyclic graphs paired with structural equations, grounding the distinction between seeing and doing. Structural equations are non-parametric: they implement discrete, rule-like relations. Whatever gradedness there is enters through exogenous variables — distributions encoding how common or rare each factor is. SCMs provide the formal machinery for counterfactual simulation models of causal selection (Icard et al., 2017; Quillien & Lucas, 2023; Gerstenberg et al., 2021), in which the responsibility of a cause \(C\) for an effect \(E\) is a function of how well \(C\) covaries with \(E\) across counterfactual worlds imagined by a subject.
My dissertation highlights the advantages of such a counterfactual simulation view, whose principle I endorse. But I also argue that the choice of SCMs as the machinery underlying counterfactual simulations is too limiting. Specifically, I argue that many of the patterns of responsibility judgments currently explained via structural models would be better understood by assuming different, neural representations of the same causal relations, representations that:
- possess more structural details than SCMs,
- break down that structure in terms of parametric functions with continuous-valued weights at the local level of pairwise connections between nodes.
This raises a classic worry: connectionist models threaten underdetermination (Massaro, 1988; Fodor & Pylyshyn, 1988): infinitely many architectures can compute any given input-output function. My dissertation proposes to circumvent this problem via an intermediate level of idealization — theories from formal semantics (Groenendijk, 2008; Link, 1983), mental model theory (Johnson-Laird, 1983; Khemlani & Johnson-Laird, 2013; Byrne, 2005), and logic programming (Robinson, 1965; Lloyd, 1984) that go beyond classical representations while remaining symbolically constrained.
Part I presents the first systematic experiments on plural causal judgments — "E happened because of A and B." The findings reveal that causal intuitions are sensitive to the structural details in our representation of causal rules that SCMs do not capture. I show how these patterns can be accounted for in terms of operations over neural representations of the same causal systems.
Part II turns to how causal selection explanations guide the acquisition of causal knowledge. I present a new rule-induction paradigm to test inference from explanations, and propose to understand the role of explanations as attentional instructions: "E happened because of A" tells a learner to pay more attention to "A" as they are trying to learn from examples. I model this using attention masks that bias gradient-based learning procedures toward rules that assign A greater importance.
Part IFrom representations to explanations
Causal selection and plural causes
Prior work has established that causal selection depends on normality: abnormal causes receive different treatment than routine ones (Hitchcock & Knobe, 2009; Icard et al., 2017). Crucially, the direction of this effect depends on causal structure. Conjunctive structures show abnormal inflation (the rare cause receives credit), while disjunctive structures show abnormal deflation (the common cause receives credit). These patterns can be captured by counterfactual simulation models of causal judgments, which say that causes receive credit to the extent that the outcome covaries with them across alternative scenarios.

These effects have been successfully modeled within the framework of SCMs. But the central claim of this dissertation is that SCMs lack the structural resources to capture all patterns in causal selection. My dissertation makes this shortcoming evident through the first systematic experiments on plural causal judgments — statements like "\(E\) happened because of \(A\) and \(B\)" (Konuk et al., under review).
Such judgments have received little systematic study, perhaps because of a tempting deflationary hypothesis: that the strength of a plural simply aggregates the independent singular judgments about each variable. Under this view, plural selection reduces to singular selection, requiring no new machinery.
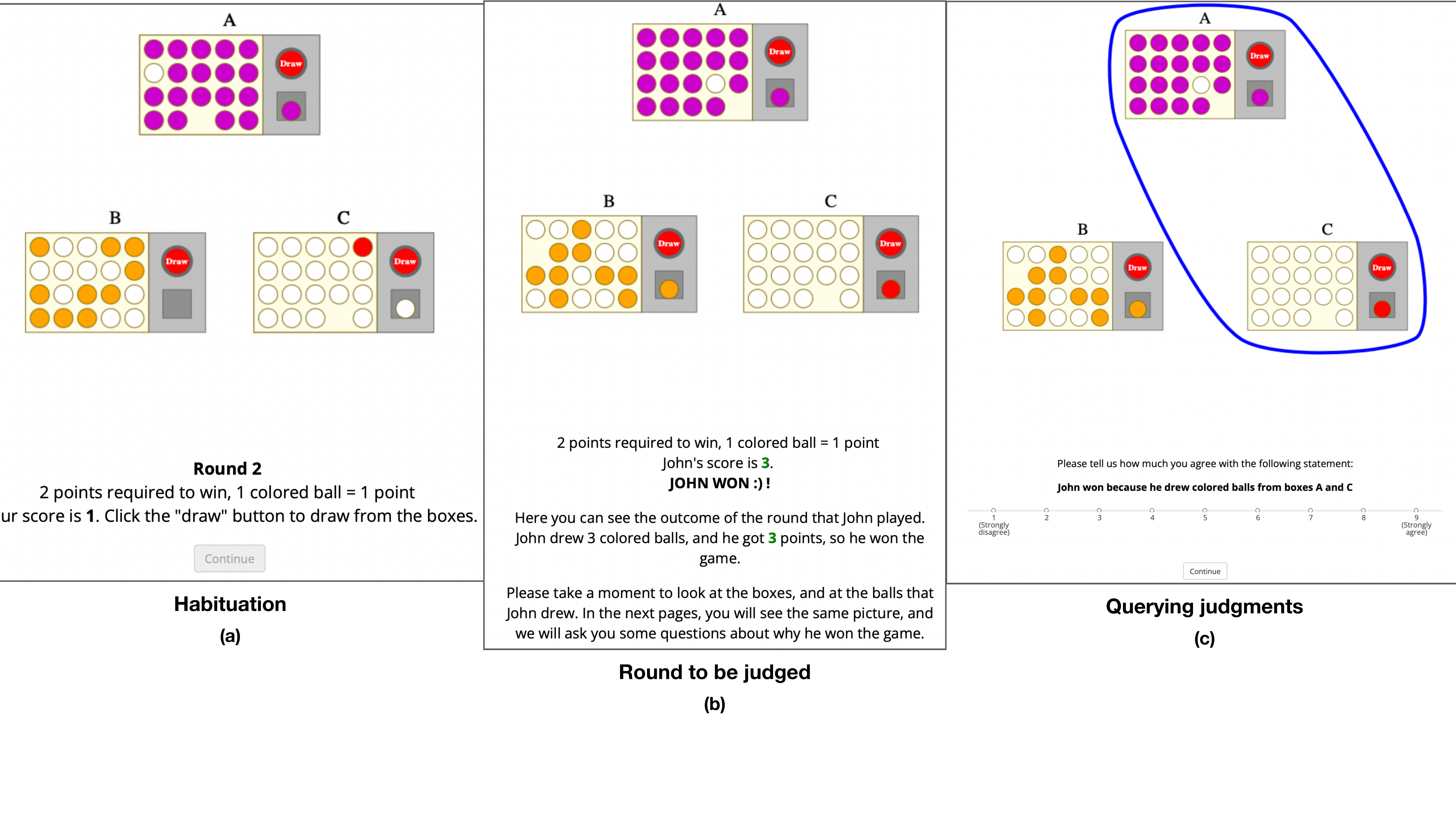
Our first experiment (presented at CogSci 2023; Konuk et al., 2023) was meant to rule out this deflationary account and establish that plural causes are a genuine phenomenon. It provided evidence that people evaluate plural causes as bona fide candidates for causal selection, entities whose counterfactual profile is apprehended directly rather than recomposed from individual constituents.
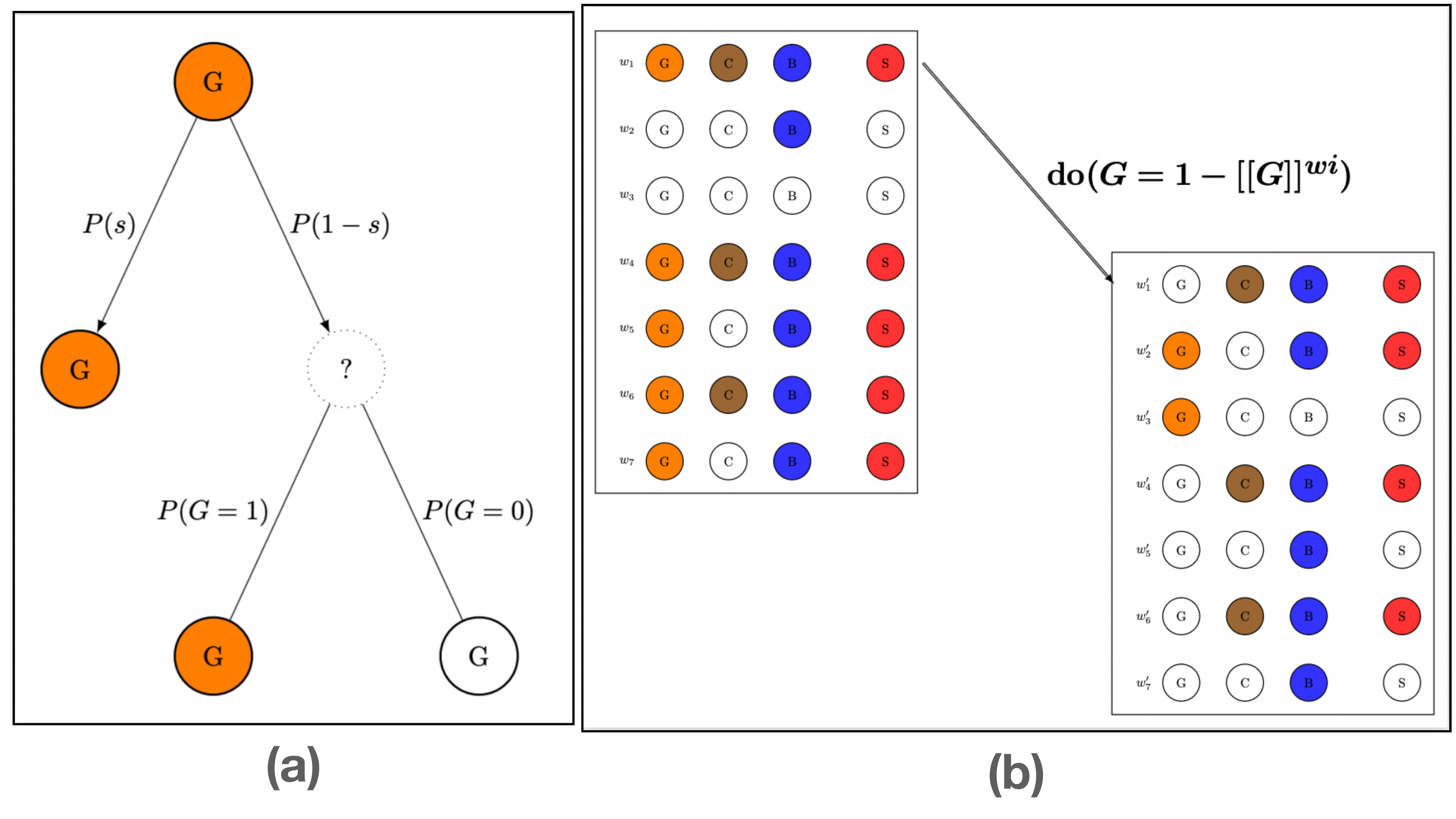
With plural causes established as a genuine phenomenon, a second experiment tested whether counterfactual theories could account for them within the framework of structural models. I designed a game with an explicitly disjunctive rule: winning required either drawing from urns \(A\) and \(B\) together, or from urns \(C\) and \(D\) together — formally:
A clear pattern emerged: participants strongly preferred "same-side" pairs — plurals whose members sit on the same route (\(A\)&\(B\) or \(C\)&\(D\)) — over "cross-side" pairs that mix variables from different routes (\(A\)&\(C\) or \(B\)&\(D\)). Same-side ratings substantially exceeded counterfactual model predictions. This provides evidence that people group causes in ways that track disjunctive structure, beyond what counterfactual dependence profiles alone can explain.
An even more striking pattern emerged for negative outcomes. Classical counterfactual theories systematically predict abnormal deflation in this setup: the urns \(B\) and \(C\) that contain the higher number of white balls should be rated highest. But participants showed the opposite — preference for urns \(A\) and \(D\) instead. Moreover, the same-side versus cross-side distinction that dominated winning rounds disappeared entirely in losing rounds.
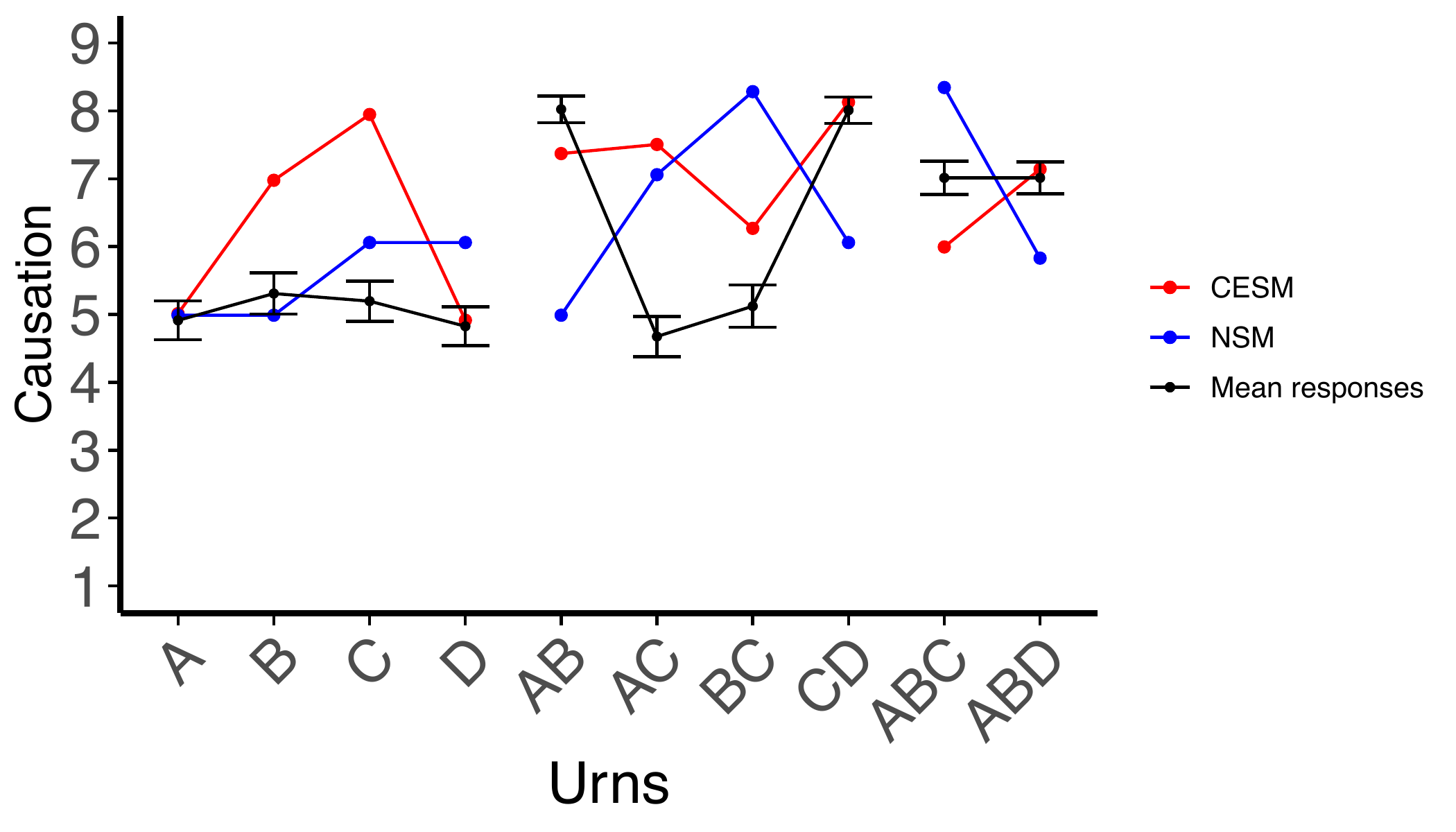
These results are deeply puzzling as they cannot be reconciled with existing counterfactual theories. I proposed an account that was able to capture these results remarkably well while staying within the framework of counterfactual simulation models. It assumes that as people score various candidate causes relative to how well they correlate with the (losing) outcome across counterfactuals, their target for what counts as a loss is not the classical negation of the winning conditions, but rather a "stronger" negation:
This hypothesis was inspired by the phenomenon of homogeneity in the natural language semantics of plural terms. Consider the sentence "The boys didn't leave." Classically, negating "The boys left" should yield "At least one boy didn't leave" — but speakers typically interpret it as "None of the boys left." Negation applies uniformly to all members of the plural, yielding a stronger reading than classical logic predicts. A model incorporating this assumption dramatically improves fit.
A new computational model of causal selection
I take the experiments above to illustrate a more general point: causal judgments depend not just on the ground truth rule underlying a causal system, but on how it is mentally represented. A central theoretical commitment of this dissertation is that we can capture this internal structure using neural architectures to model the cognitive machinery that underlies the production of causal judgments.
I say that the simulation processes by which we generate counterfactuals and elaborate causal explanations unfold over neural networks with richer structure than Structural Causal Models typically encode. In these neural models, intermediate layers track which combinations of variables form coherent pathways to an outcome.
The two disjuncts in \((A \land B) \lor (C \land D)\) translate into two distinct hidden nodes (\(H_1\) and \(H_2\)), each tracking whether its corresponding "route" to the outcome is satisfied. The routes that subjects track in their causal judgments thus correspond to separable subnetworks in the model.
One might worry that this proposal faces a classic problem for connectionist approaches. For any rule like the one above, infinitely many networks could compute the same truth function, including architectures quite different from the one I propose. What principled reason do we have to prefer one over another?
I argue that this underdeterminacy problem can be circumvented by appealing to an intermediate level of representation: that of symbolic theories of computation. I turn to the framework of logic programming. The central idea is that representing a logical relation requires executing a procedure that can derive \(E\) from \(A, B, C, D\). The class of general logic programs represents the simplest class of programs that can represent such a rule. It consists of sets of Horn clauses, each specifying how to derive a conclusion from premises:
Each clause represents one "route" to establishing \(E\). This modular structure is independently supported by theories of mental representation. Both mental model theory and inquisitive semantics propose that people represent disjunctions as collections of distinct alternatives rather than flat Boolean formulas.
Logic programs also illuminate the asymmetry between positive and negative outcomes. Proving \(E\) is existential: find one clause whose body is satisfied. Proving \(\sim E\) (negation-as-failure) is universal: verify that every route to \(E\) fails. When cashed out in the machinery of neural models, this asymmetry gives us a way to explain both the collapse of same-side structure and the reversal from abnormal deflation to abnormal inflation for losses.
To cash out these symbolic constraints in neural terms, I appeal to the CILP neuro-symbolic translation algorithm (Garcez et al., 2002), which systematically compiles logic programs into three-layer neural networks with one hidden node per clause. The architecture is no longer arbitrary: it is tethered to the clause structure of the source program.
Counterfactual sampling and weight updates
But specifying the architecture is only half the story. My dissertation also proposes a theory of the processes by which these representations are computed over. The core idea is that people stress-test their internal models: they simulate counterfactual scenarios, and these simulations incrementally adjust connection weights. This weight adjustment models the cognitive work of pondering each cause's contribution; the accumulated weights then ground the final importance judgment.
This troubleshooting process unfolds in three stages. First, starting from the observed actual world, subjects explore neighboring counterfactual states via an MCMC process following the mutation sampler model of Davis & Rehder (2020). At each step, they consider flipping one input variable's value. Transition probabilities depend on two factors: the normality of the event and whether the proposed change would alter hidden node activations from the previous steps.

In each sampled state, subjects update their internal models' weights using Layer-wise Feedback Propagation (LFP; Weber et al., 2025). The key insight is that connections strengthen when pre- and postsynaptic signals align, and weaken when they oppose. This produces abnormal deflation at the hidden-to-output layer (normal routes gain credit) and abnormal inflation at the input-to-hidden layer (the absent input that deactivated a hidden node gains credit).
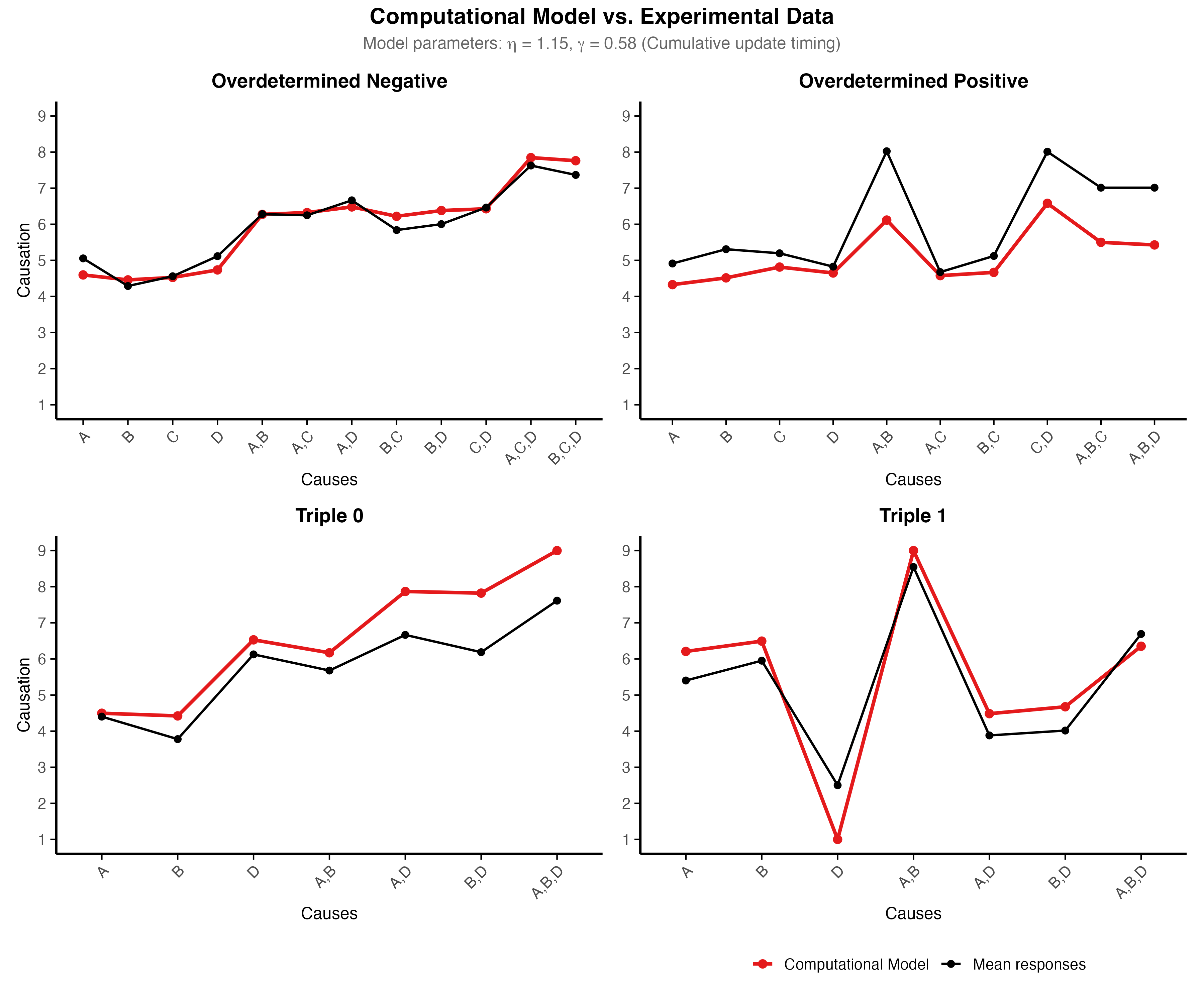
This mechanism captures the asymmetry between positive and negative outcomes observed in Experiment 2: for wins, sampling concentrates on the satisfied route, so hidden-layer deflation dominates and same-side structure emerges; for losses, all routes must be checked, input-layer inflation takes over, and surprising failures gain credit.
After sampling, causal importance is computed via Layer-wise Relevance Propagation (LRP; Bach et al., 2015), which distributes credit backward through the updated weights. The final importance score divides summed relevance by path complexity:
where \(\mathcal{C}(C, O)\) counts edge-disjoint active routes. This parsimony term explains the same-side preference: causes operating through a single route score higher than those spreading across multiple routes.
The coherence of these stages is crucial: hidden nodes influence which counterfactuals are sampled, weight updates accumulate evidence about causal pathways, and relevance propagation reads off the result.
Part IIFrom explanations to learning
The inference-from-explanation puzzle
Part II turns to the converse question: how do causal explanations guide the acquisition of causal knowledge? An explanation like "E happened because of C" deliberately omits most of the causal picture, singling out one variable from among many that might matter. Yet such sparse signals seem remarkably effective: everyday explanations help us learn the structure of unfamiliar causal systems. How can mentioning a single cause guide inference about a rule that may involve several variables in complex combinations?
Experimental evidence
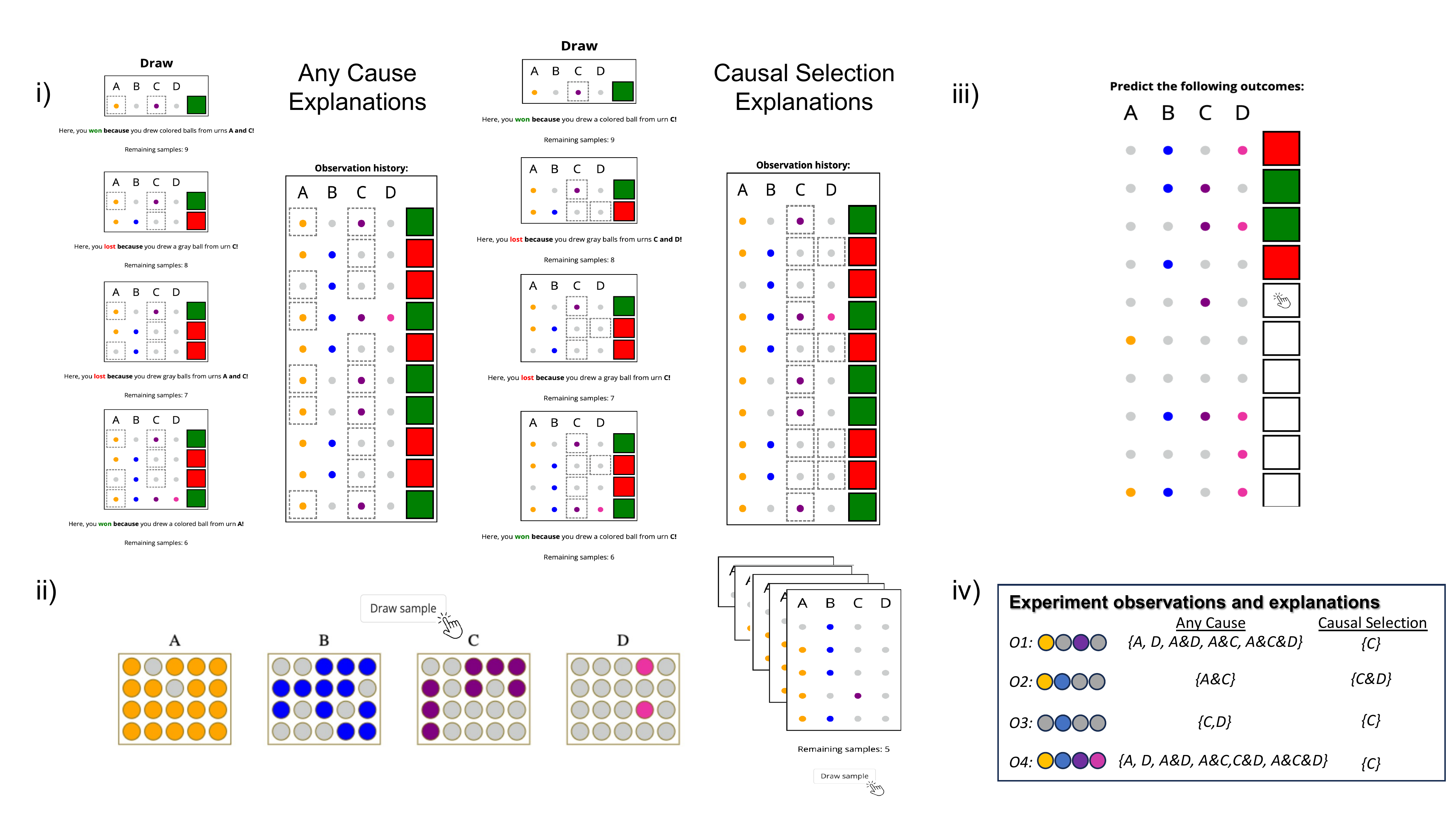
I co-developed a new paradigm to study this phenomenon (presented at CogSci 2024; Navarre et al., 2024), using the same urn-sampling setup as Part I.
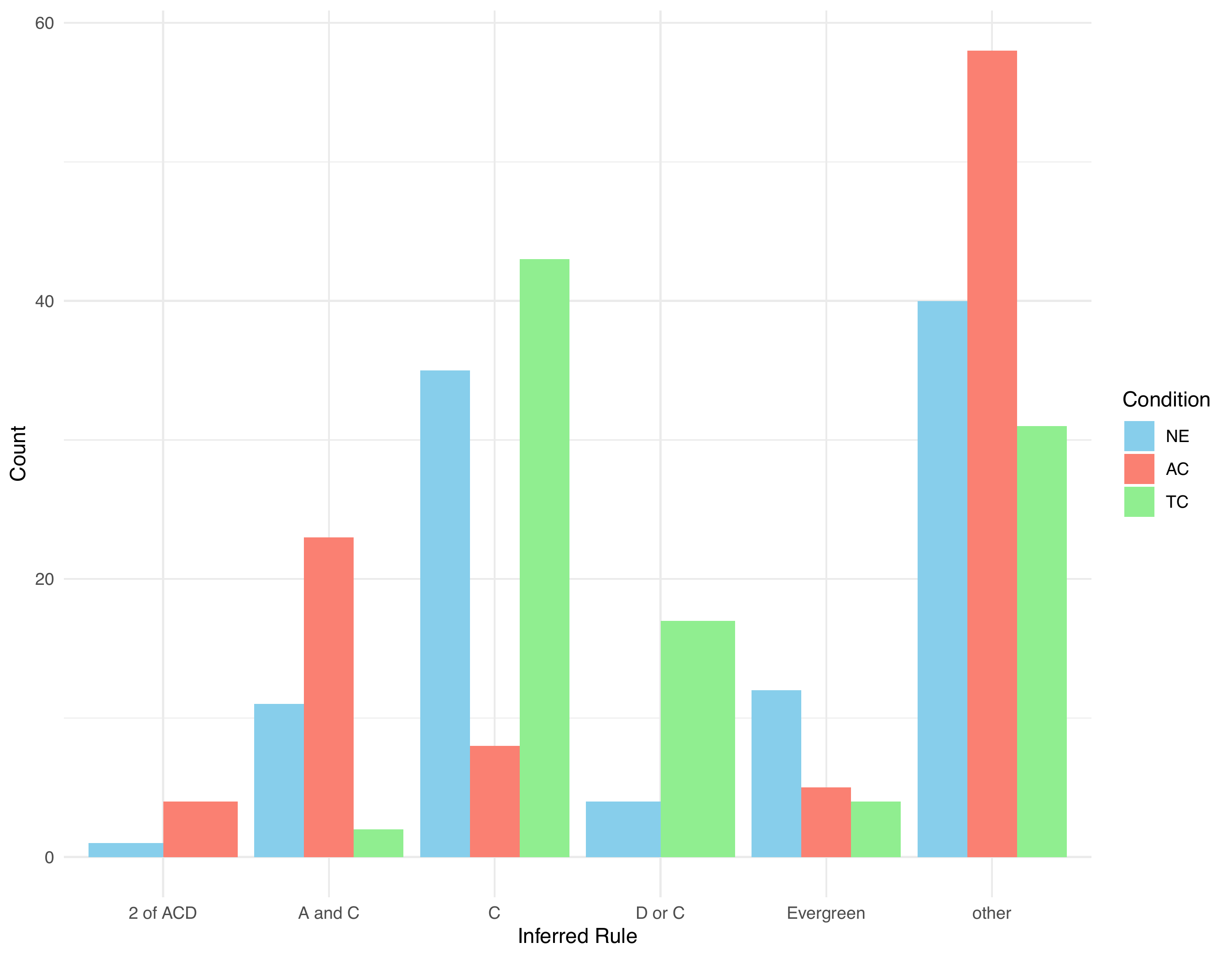
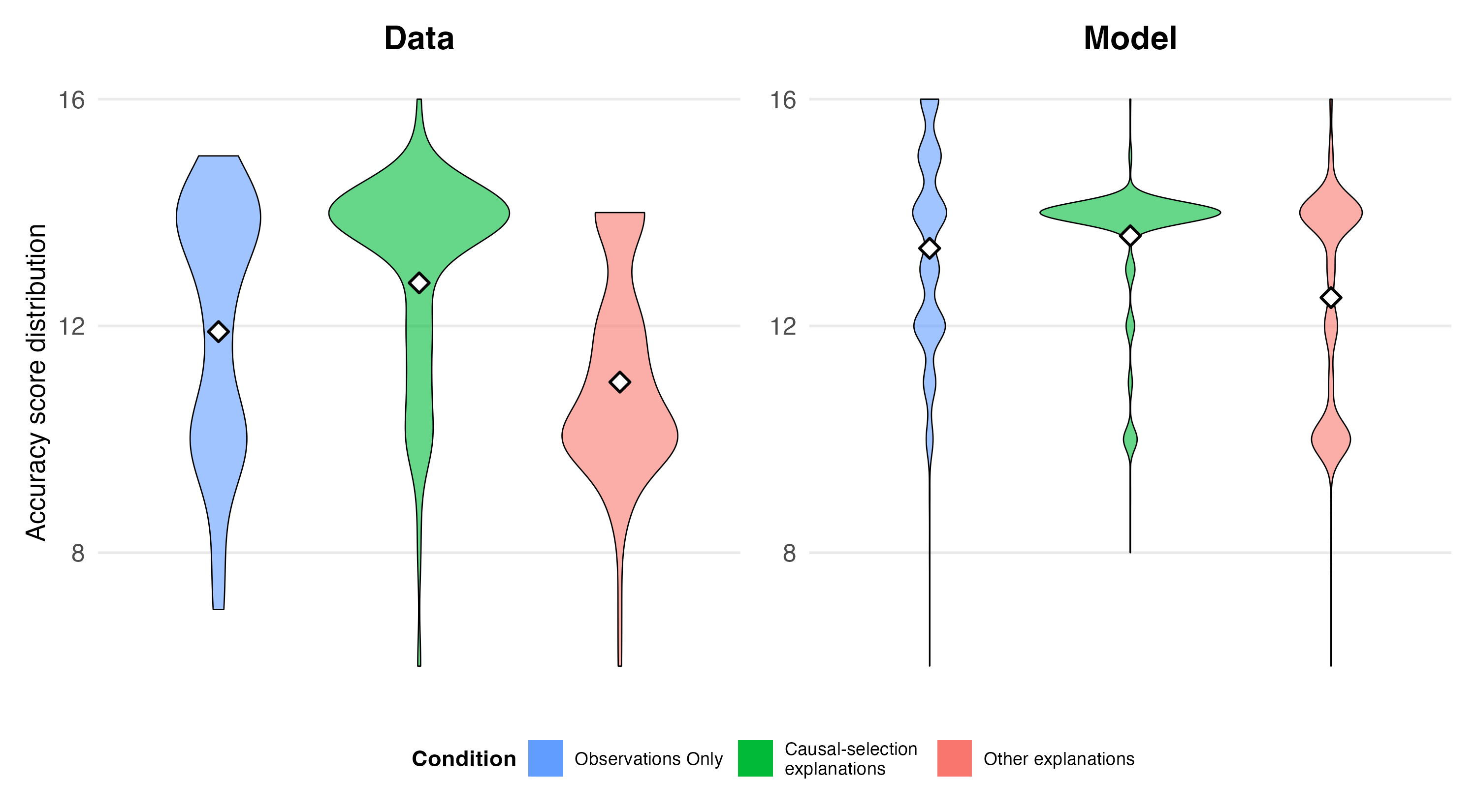
The experiment yielded three key findings: (i) participants who received causal selection explanations (CS) inferred the correct rule significantly more often than those who saw observations alone (OBS); (ii) participants who received explanations citing any causally relevant variable (AC) performed worse than OBS, despite receiving additional information; and (iii) participants in the CS and OBS conditions showed a striking preference for the simple rule W := C, even though one CS explanation ("You lost because of C and D") should have ruled it out.
Two accounts offer competing explanations for these patterns. The first is reverse-engineering: the learner treats explanations as Gricean signals, reasoning "If the explainer chose to say 'because of C,' they must believe C is the decisive factor — so I should favor hypotheses where C plays the key role." Formally, the learner infers the explainer's beliefs by asking which hypotheses would lead a rational speaker to produce that explanation.
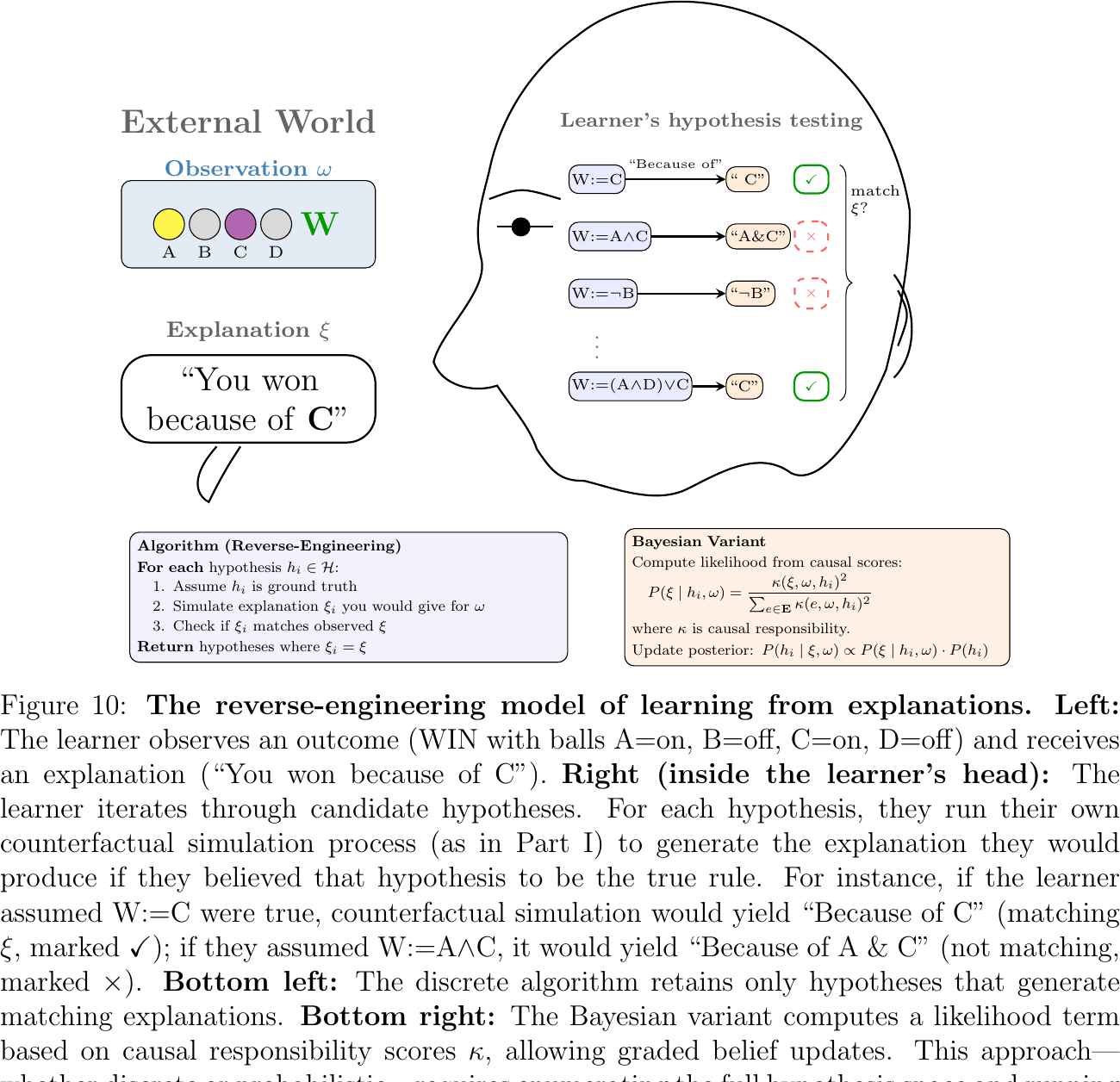
I propose an alternative, attention-based account. Rather than inferring what the explainer believes, the learner treats explanations as instructions to attend to certain variables during learning. Mentioned variables are amplified; others are attenuated. More gradient signal then flows through attended inputs, biasing the learner toward rules that assign those variables greater importance.
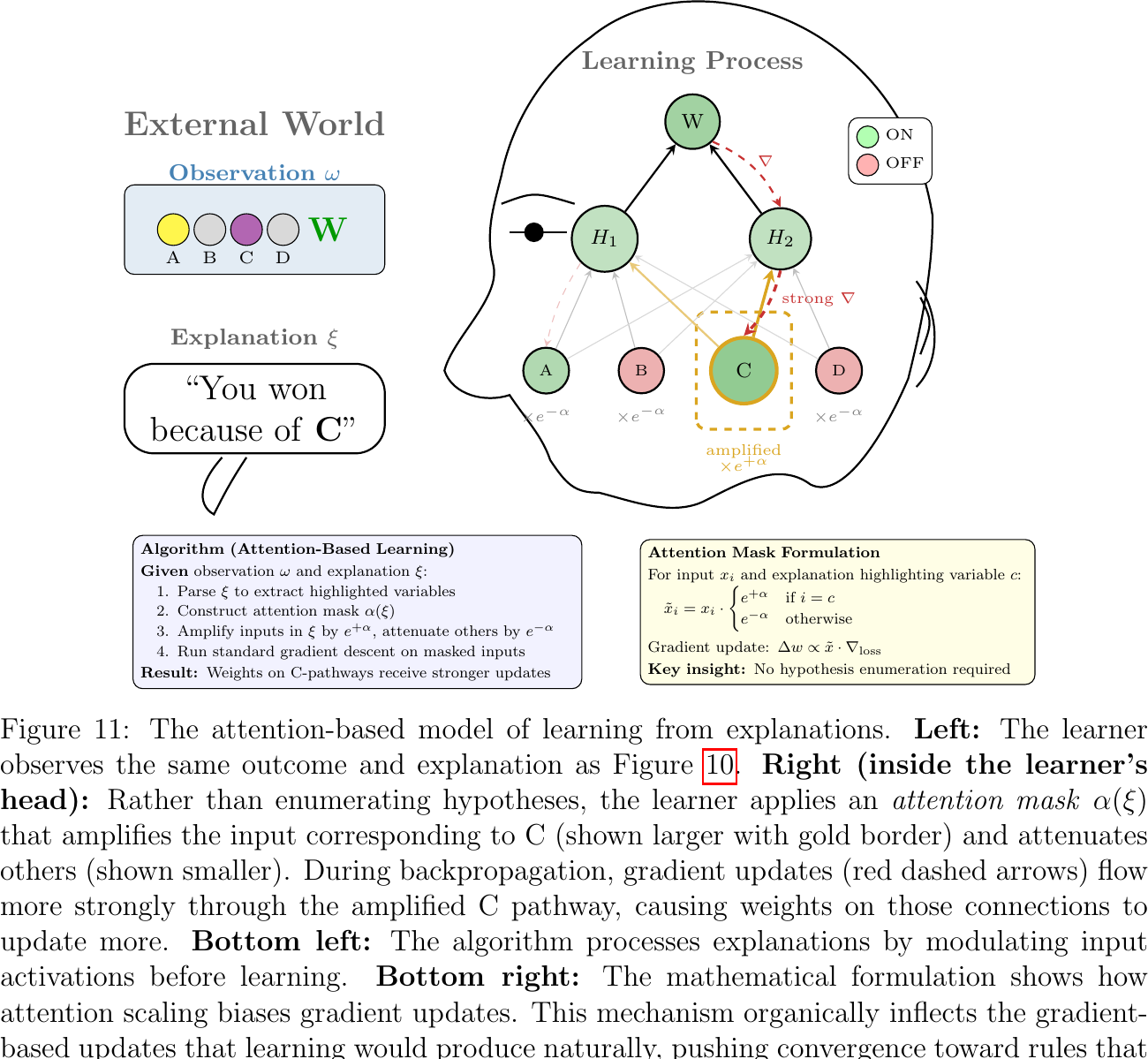
Three considerations favor the attention-based account.
First, reverse-engineering cannot explain the W := C preference: if a learner hears "You lost because of C and D," they should infer at a minimum that the explainer believes both C and D matter, ruling out W := C entirely. Yet that rule remained participants' most popular response. Attention explains this: about half the CS explanations mentioned C alone, so attention to C accumulated across trials, enabling incremental convergence despite one contradicting explanation.
Second, reverse-engineering struggles with the AC decrement: any parameter settings that make W := C the model's top prediction also predict that AC should outperform OBS, the opposite of what we observed. Attention can accommodate the decrement: attending to less diagnostic variables may divert gradient signal from critical ones, hindering learning.
Third, attention has a decisive advantage in computational tractability. Reverse-engineering requires enumerating the hypothesis space and running counterfactual simulations for each candidate, scaling poorly as variables increase. Attention sidesteps this by integrating inference from explanations directly into the learning process by which people infer rules from examples.
Conclusion
This dissertation proposes a new theory of the internal representations that support human causal understanding. It bridges the gap between symbolic theories of causal reasoning and subsymbolic neural computation to offer a unified account of how we produce and evaluate explanations, and how we learn from the explanations of others.
Part I presents the first systematic experiments on plural causal judgments, revealing that people track representational structure — routes, groupings, surprising failures — that standard formal models do not encode. I account for these patterns using neural architectures that model the internal machinery of human causal understanding.
Part II proposes that causal explanations guide learning by directing attention during gradient-based learning. A common thread connects both: graded causal intuition emerges from continuous weight parameters in our internal representations.
This common thread weaves together insights from psychology, AI, linguistics, and philosophy into a coherent research program — one that grounds human causal cognition in neural computation and illuminates how explanations transfer causal knowledge.